
자바는 어떻게 실행되나요?
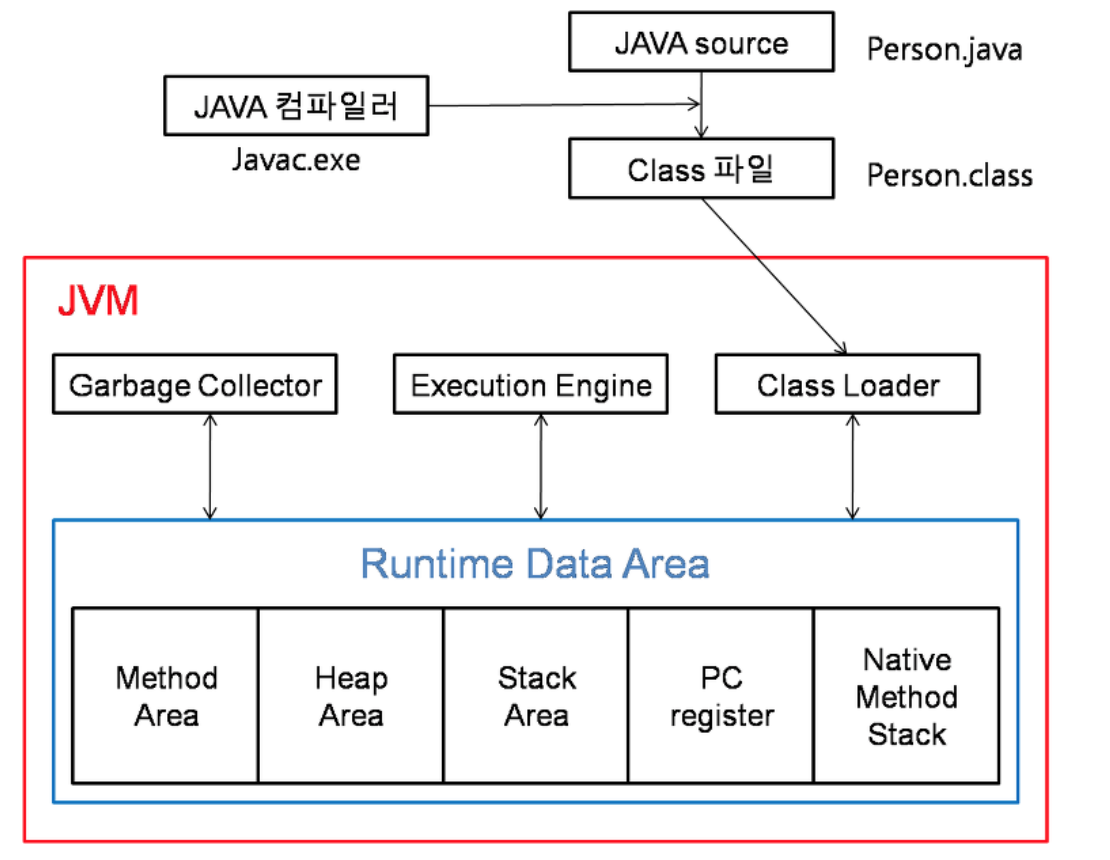
컴파일러가 자바 소스코드를 바이트코드로 변환합니다.
그 다음 JVM의 클래스 로더가 바이트 코드를 런타임 데이터 영역에 로드시키고, 로딩된 바이트 코드가 JVM의 실행엔진에 의해서 실행되게 됩니다.
💭 해당 질문의 배경 지식
💡 자바 실행환경
자바는 운영체제(OS)에 종속적이지 않다는 특징을 가진다.
운영체제에 종속받지 않고 실행될 수 있는 이유는 운영체제 위에서 자바를 실행시키는 JVM이 있기 때문이다.
자바의 JVM은 운영체제에 종속받지 않고 자바를 실행할 수 있게 하는 가상 머신이다.
JVM은 운영체제에 종속적이므로, 각 운영체제에 맞는 JVM을 설치해야한다.
그럼 어느 운영체제든 Java 파일 하나만 만들면 각자의 운영체제에 맞는 JVM 위에서 실행할 수 있게된다.
즉, 자바는 운영체제 위에서 JVM(Java Virtual Machine)이라는 것을 통해 프로그램이 돌아가기 때문에 운영체제별로 따로 개발을 할 필요가 없다는 장점이 있어 많이 사용되는 개발 언어이다.
💡 자바 애플리케이션 실행 과정
1. 개발자가 작성한 소스코드가 ".java" 파일로 저장 된다.
2. 자바 컴파일러가 이 소스코드를 JVM이 읽을 수 있는 바이트 코드로 컴파일(complie)하고, 이 바이트 코드는 ".class" 파일로 저장이 된다.
3. JVM에 클래스 로더(Class Loader)가 바이트 코드를 불러와서, 자바의 메모리(Runtime Data Area)에 올려둔다.
4. JVM에 실행 엔진(Execution Engine)이 메모리에 올려둔 것들을 실행한다.
자바 메모리 구조가 어떻게 되어 있나요?
자바 메모리 구조는 크게 5가지 영역으로 구분됩니다.
우선 스레드마다 PC Register, JVM Stack 그리고 Native Method Stack이 있고, 스레드 공통으로는 Heap과 Method Area가 있습니다.
PC Register에는 현재 수행중인 JVM 명령어가 들어있고, JVM Stack은 호출된 메소드의 매개변수, 지역변수, 리턴정보들이 저장됩니다. 그리고 Native Method Stack은 자바 외의 언어인 C나 C++같은 것들을 수행하기 위한 영역입니다.
Method Area는 클래스 별로 전역변수, 정적 변수, 메소드 정보들이 저장되며,
마지막으로, Heap 영역은 런타임 중 생성되는 객체들이 동적으로 할당되는 영역입니다.
💭 해당 질문의 배경 지식
💡 자바 메모리 구조
- 스레드별 : PC Register, JVC Stack, Native Method Stack
- 공통 : Method Area, Heap
| 스레드별 | PC Register | 현재 수행중인 JVM 명령어를 저장 |
| Stack | 메소드에 대한 정보(매개변수, 지역변수, 리턴값 등)를 저장 | |
| Native Method Stack | 자바 외의 다른언어로 작성된 코드를 저장 | |
| 공통 | Heap | 사용자가 사용하면서 생성된 데이터 즉, 동적 할당된 데이터를 저장 |
| Method Area | 각 클래스 별 전역변수, 정적변수, 메소드 정보를 저장 |
가비지 컬렉션(GC)이 뭔가요?
GC는 JVM에서 메모리를 관리해주는 모듈입니다.
Heap 메모리를 재활용하기 위해 더 이상 참조되지 않는 객체들을 메모리에서 제거하는 모듈입니다.
개발자가 직접 메모리를 정리하지 않아도 되서 개발 속도가 향상되는 장점이 있지만,
Mark And Sweep이라는 참조되지 않는 객체를 찾는 과정이 있는데, 이때 스레드가 잠깐 중단되어서 성능이 떨어진다는 단점이 있습니다.
💭 해당 질문의 배경 지식
💡 가비지 컬렉션
- JVM에서 메모리를 관리해주는 모듈이다.
💡 메모리를 관리한다?
예전에는 개발자가 직접 메모리를 관리해줘야 했다.
메모리를 낭비하지 않기 위해 쓰이지 않는 데이터들을 지워주는 즉, 메모리를 비워주는 작업을 해줘야 했는데
자바에서는 이러한 것을 "가비지 컬렉션"이 자동으로 해준다.
가비지 컬렉션은 이러한 것을 어떻게 수행할까?
코드가 실행되면서 메모리가 점점 차면 잠깐 실행을 멈추고, 메모리에 있는 데이터가 각각 어디에서 참조되고 있는지 확인한다. 참조되고 있지 않은 데이터가 있다면 없애 메모리 공간을 확보한다.
이렇게 잠깐 멈춘 뒤 안쓰는 데이터를 찾는 과정을 "Mark And Sweep"이라 한다.
객체지향 프로그래밍이 뭔가요?
현실 세계의 사물과 같은 객체를 만들고 그 객체에서 필요한 특징을 뽑아서 프로그래밍을 수행하는 것입니다.
객체지향 프로그래밍은 총 4가지 특징이 있는데요, 추상화, 캡슐화, 상속성, 다형성입니다.
💭 해당 질문의 배경 지식
💡 객체지향 프로그래밍
- 현실 세계의 사물같은 객체를 만들고, 객체에서 필요한 특징을 뽑아 프로그래밍 수행하는 것
💡 객체지향 프로그래밍의 특징
| 추상화 | 공통적인 특징을 뽑아내는 것 |
| 캡술화 | 객체들 안에 정보를 정보은닉을 통해 내부적으로 높은 응집도를 갖고, 외부적으로 낮은 결합도를 갖도록 하는 것 |
| 상속성 | 부모클래스의 속성과 기능을 그대로 이어 받아 재사용할 수 있도록 하는 것 |
| 다형성 | 하나의 변수, 함수명 등이 상황에 따라 다른 의미로 해석될 수 있는것 대표적인 예로 오버라이딩과 오버로딩이 다형성을 나타낸다. |
추상클래스와 인터페이스의 차이점이 뭔가요?
추상클래스는 abstract 지시자로 정의되어서 추상메소드가 하나 이상 포함된 클래스이고,
인터페이스는 interface 지시자로 정의되어서 모든 메소드가 추상메소드로 정의되는 클래스입니다.
추상클래스와 인터페이스의 차이는 그 존재의 목적에 있습니다.
추상 클래스는 상속받아서 기능을 재활용하고 확장시키는데 그 목적이 있다 하면,
인터페이스는 메소드의 구현을 강제해서 구현한 객체들이 같은 동작을 하는것을 보장하는데에 그 목적이 있습니다.
💭 해당 질문의 배경 지식
💡 추상클래스 vs 인터페이스
| 종류 | 지시자 | 설명 | 사용 목적 |
| 추상 클래스 | abstract | 추상메소드가 1개 이상 포함된 클래스 |
상속을 위함 상속을 받아 부모 클래스의 기능을 자식클래스에서 재활용 및 확장하기 위해 사용 |
| 인터페이스 | interface | 모든 메소드가 추상메소드로 정의된 클래스 |
기능 보장을 위함 인터페이스를 구현한 객체들이 모두 같은 기능을 동작할 수 있음을 보장하기 위해 사용 |
Reference